榨干3000元显卡,跑通千亿级大模型的秘方来了 | 中国贸易报-凯发网址
导读
用几块3000元显卡作为加速主力的一体机,就能跑通671b的deepseek。
放在个把月前,你敢想象这样的场景么?
正在埋头苦干,希望有更多样化产品交付的一体机厂商们,pick英特尔锐炫™ 显卡 至强® w 处理器这套组合拳,首要原因就是它的成本确实诱人——基本算是砍掉了一个数量级(下线可以控制在10万元以内)。
其次就是这套组合也很能打,上面那个场景就是它目前的“标杆式”战绩。
这两点加起来就是“真香”定律的复现。
但别光说不练,这种极具性价比的一体机实测的体感到底如何呢?
带着这个问题,我们直接上手亲自测试了一波。
例如我们先用qwq-32b离线状态下问了个经典题目:
>9.9和9.11哪个大?
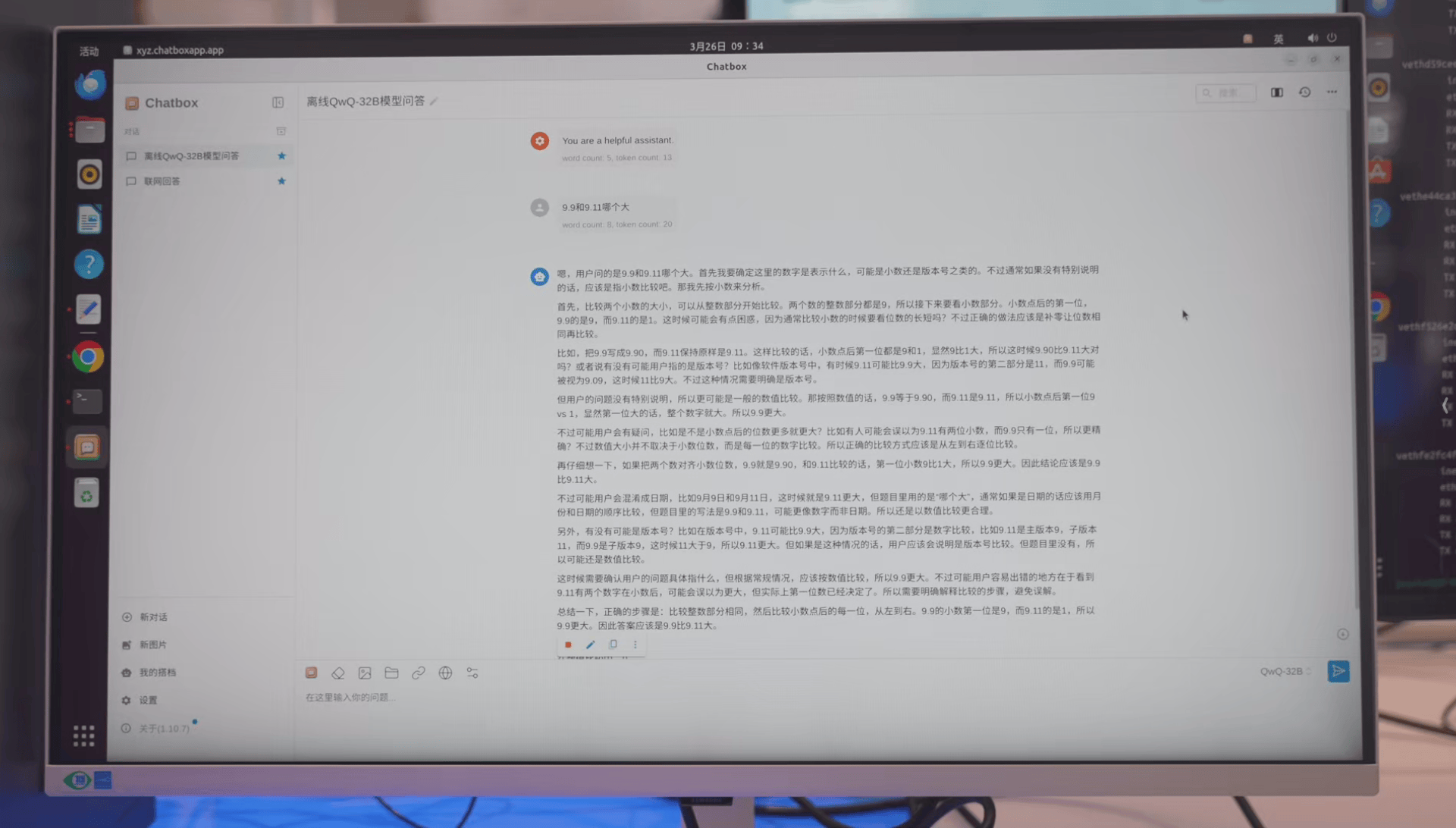
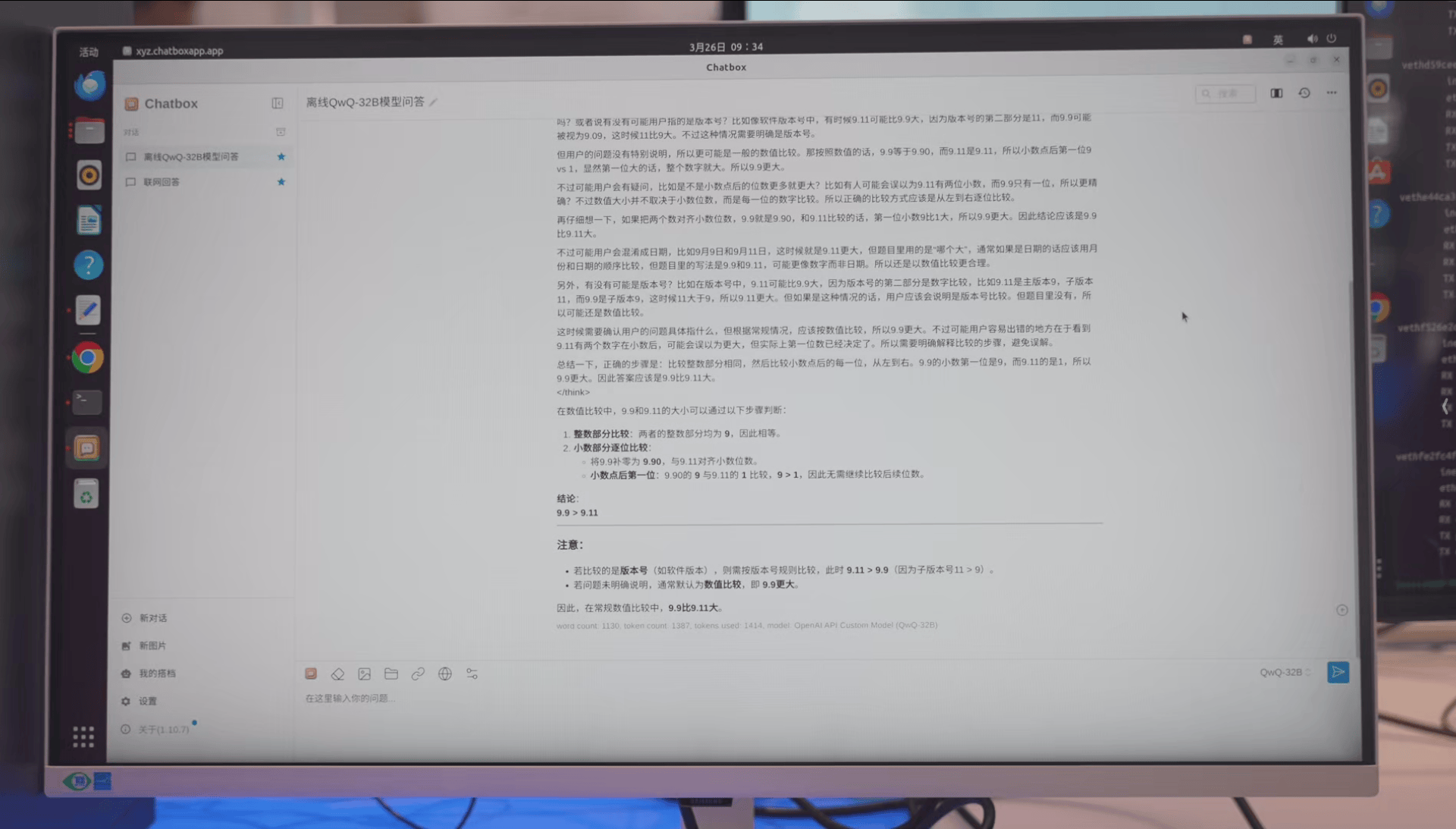
从效果上来看,若是**单人**使用,一体机的速度已经达到了**32 tokens/s**。
讲真,这个速度在体感上已经是非常ok了。
而且这还不是个偶然事件,在同样的情况下,我们再问一个问题:
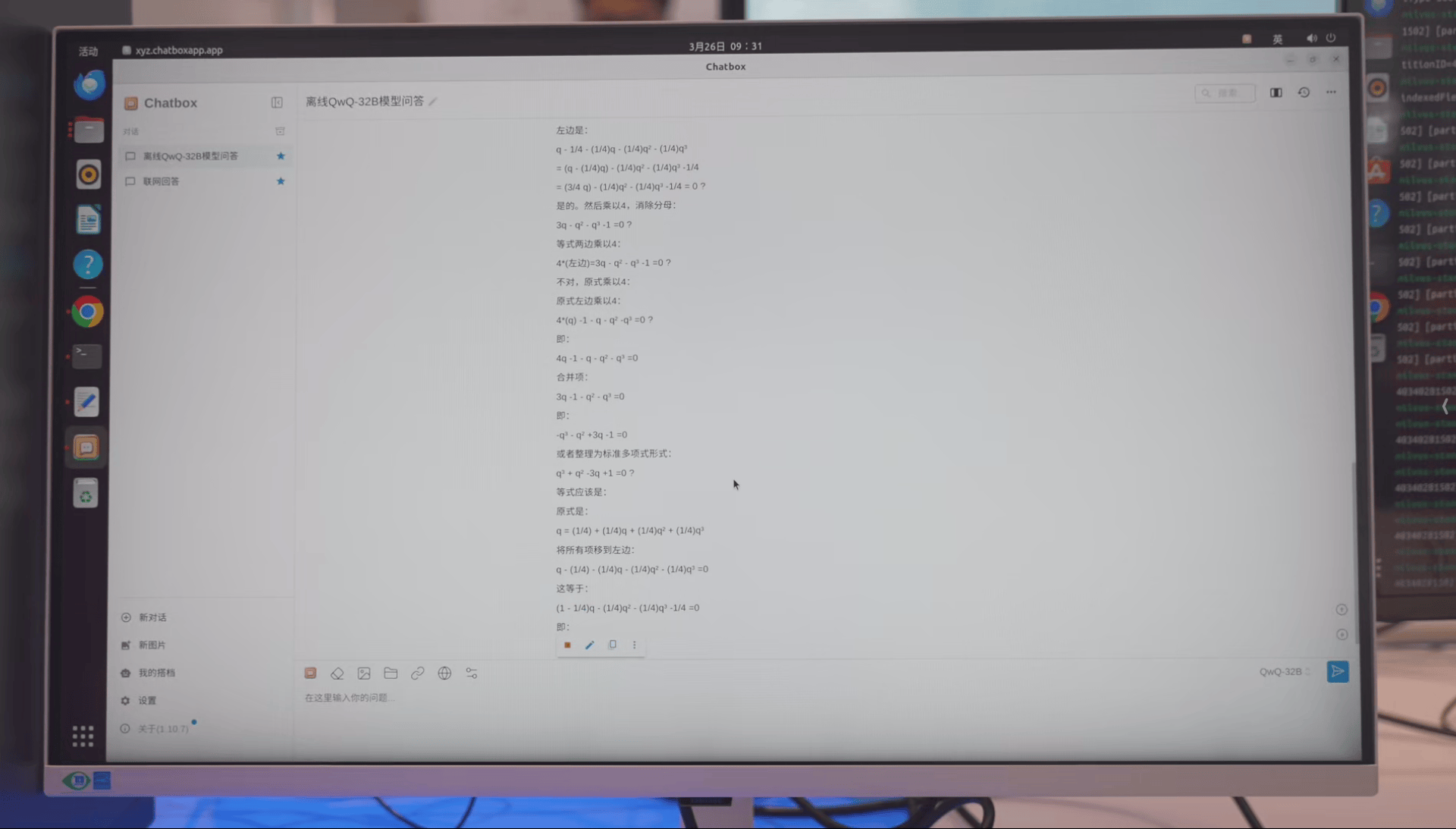
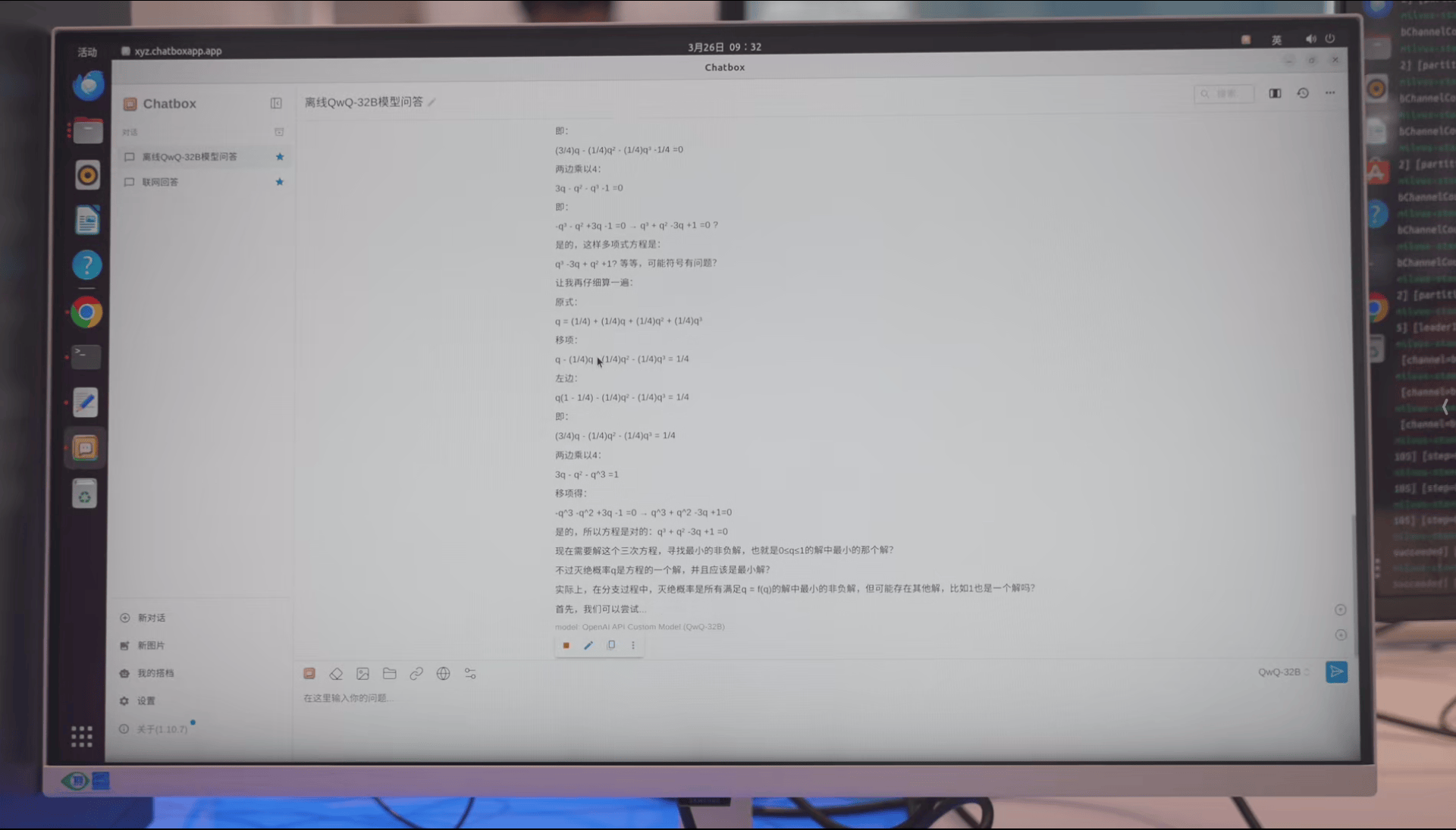
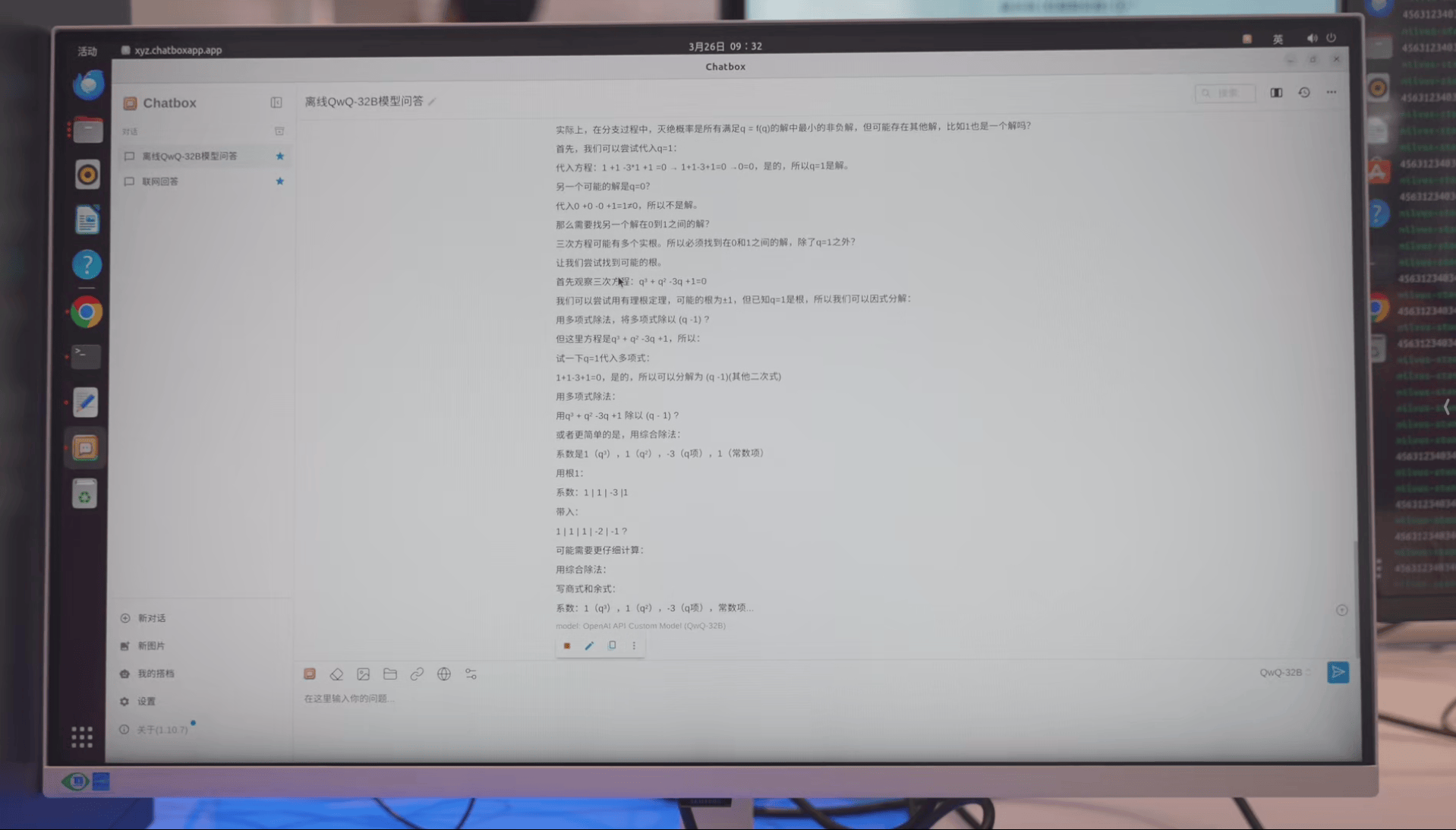
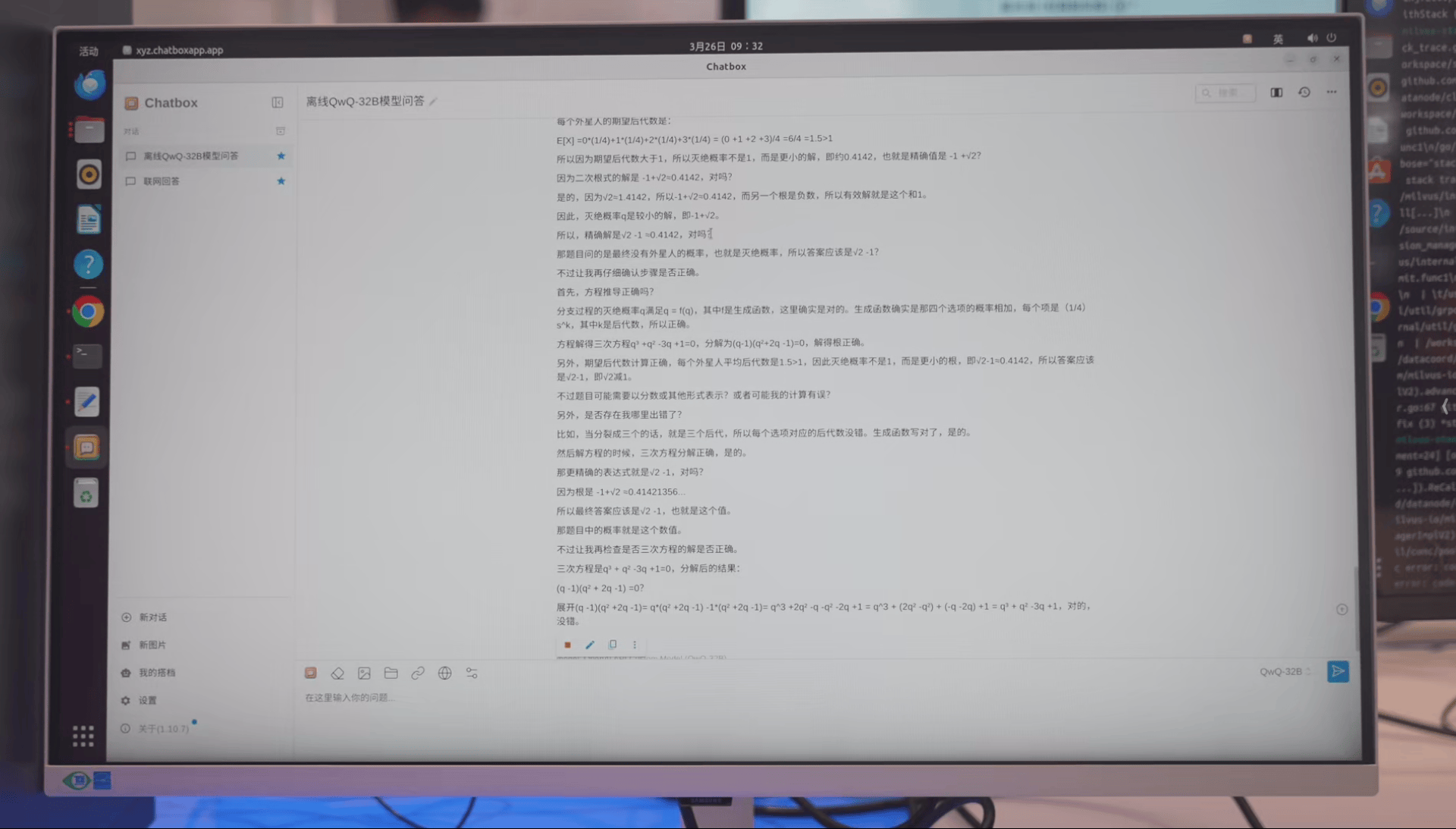
>一个外星人来到地球后等可能选择以下四件事中的一件完成:
>1,自我毁灭;
>2,分裂成两个外星人;
>3,分裂成三个外星人;
>4,什么都不做。
>此后每天,每个外星人均会做一次选择,且彼此之间相互独立。
>求地球上最终没有外星人的概率。
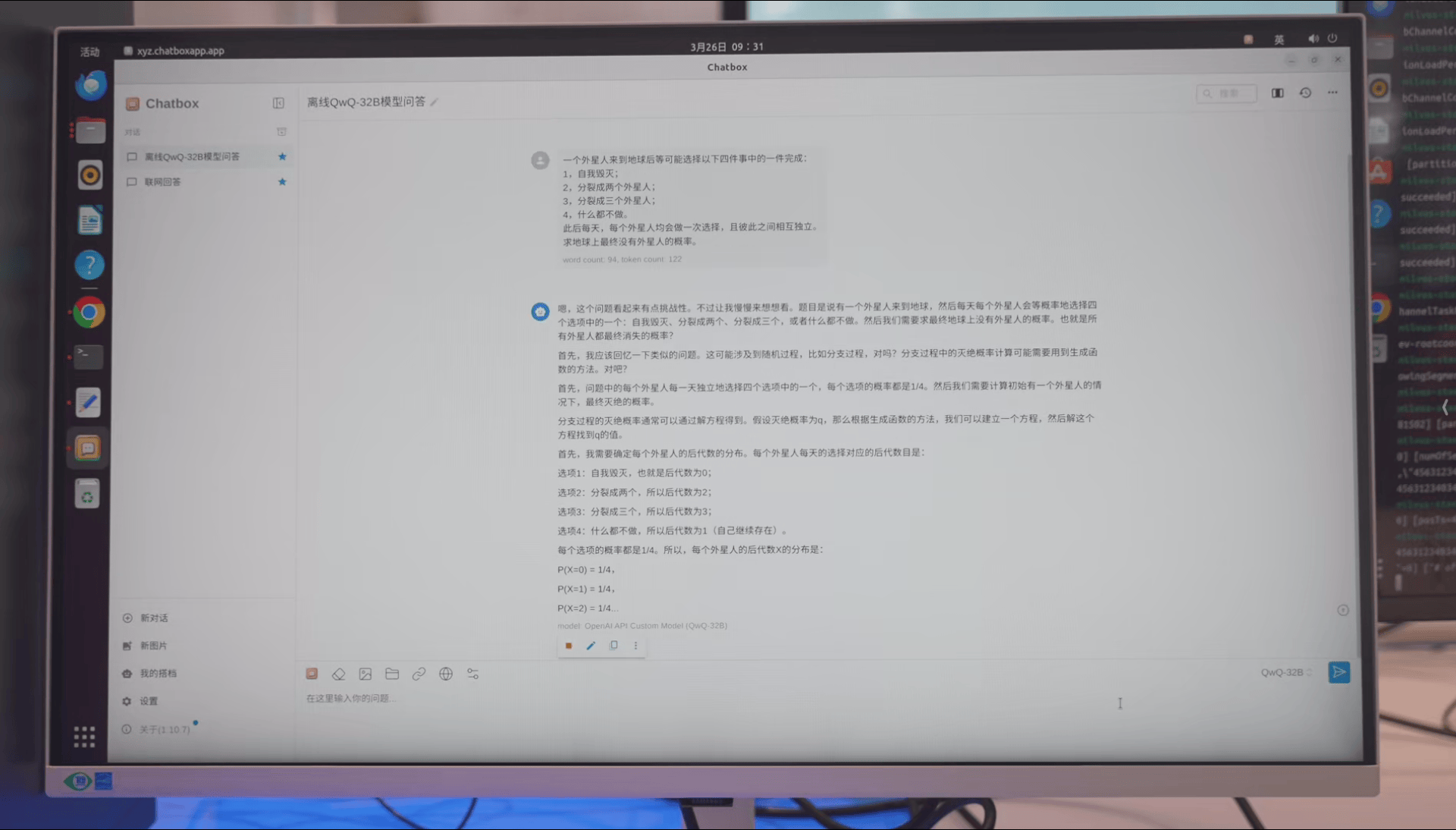
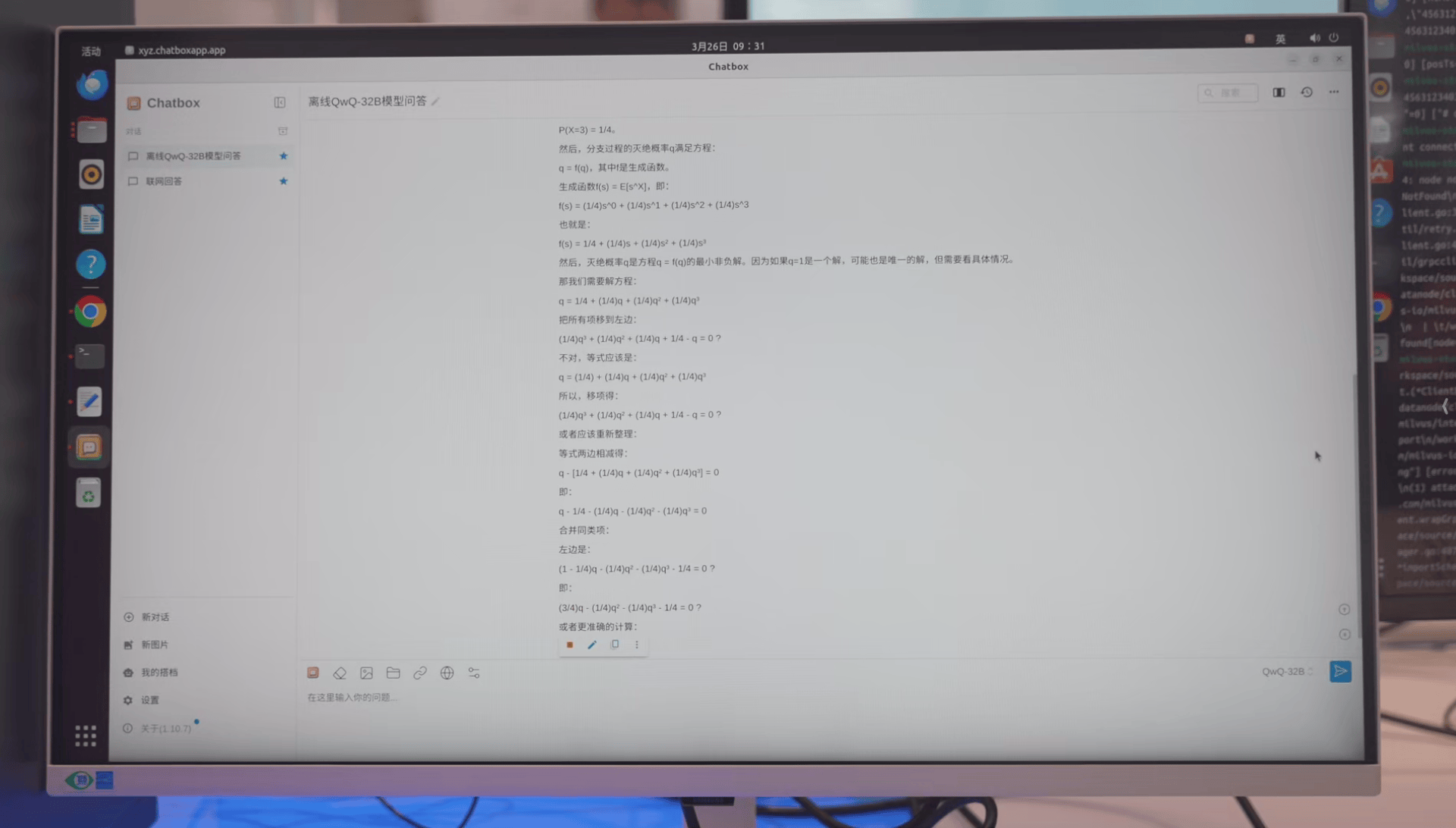
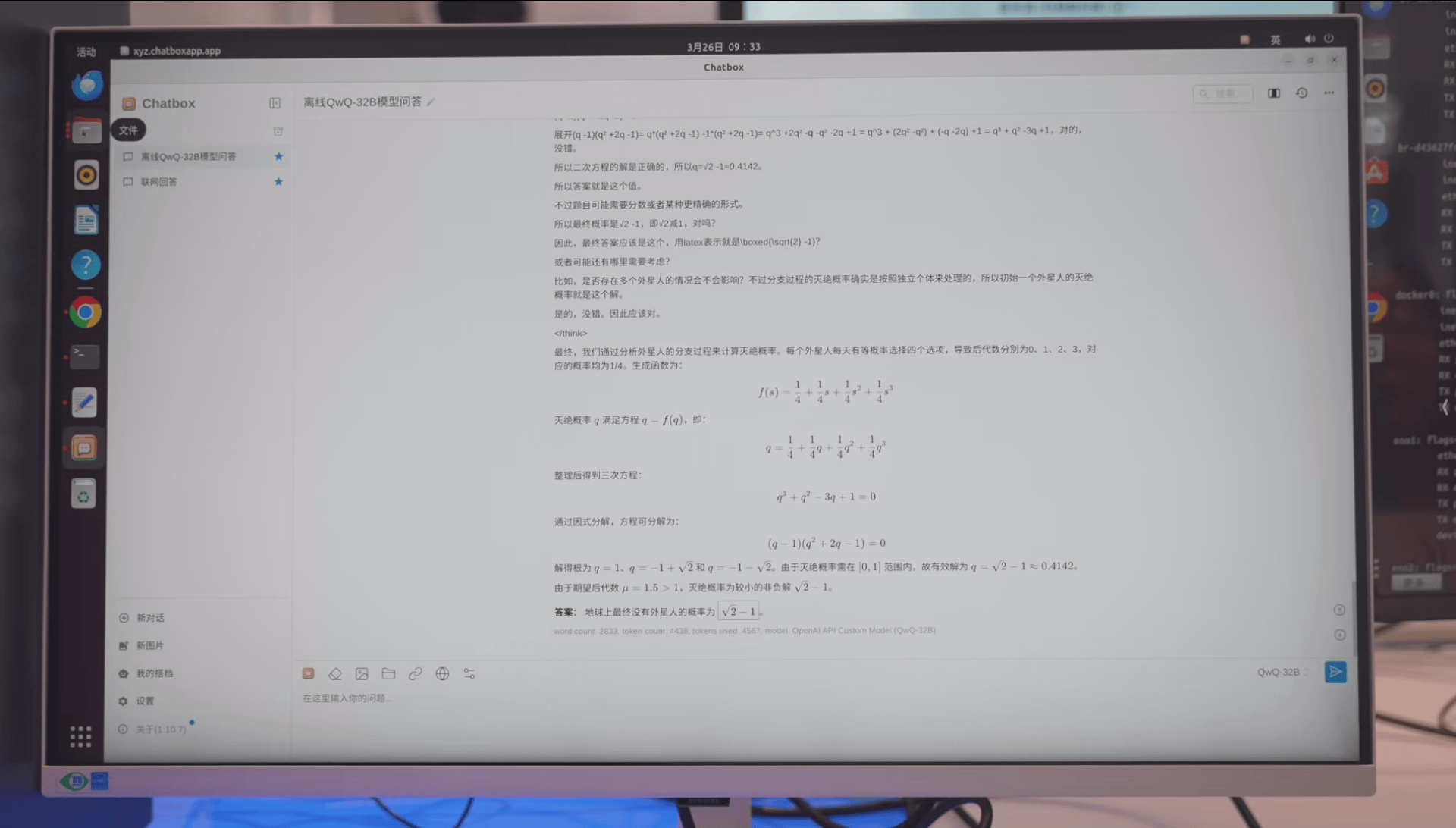
同样的,输出速度依旧是非常的快。
而当同时使用人数增加时,我们做了初步的计算,其每秒tokens的速度大概是这样的:
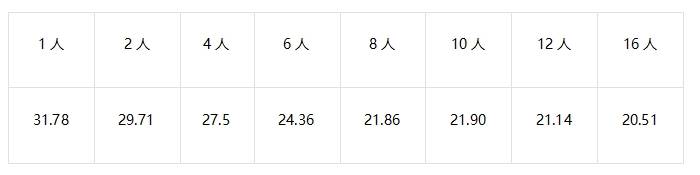
那么如果是地狱难度的671b deepseek r1,结果又会如何呢?
毕竟即便是q4量化版本,以往承载它的一体机成本动辄就要达到200万元。
请听题:
>一个汉字具有左右结构,左边是木,右边是乞。这个字是什么?只需回答这个字即可。
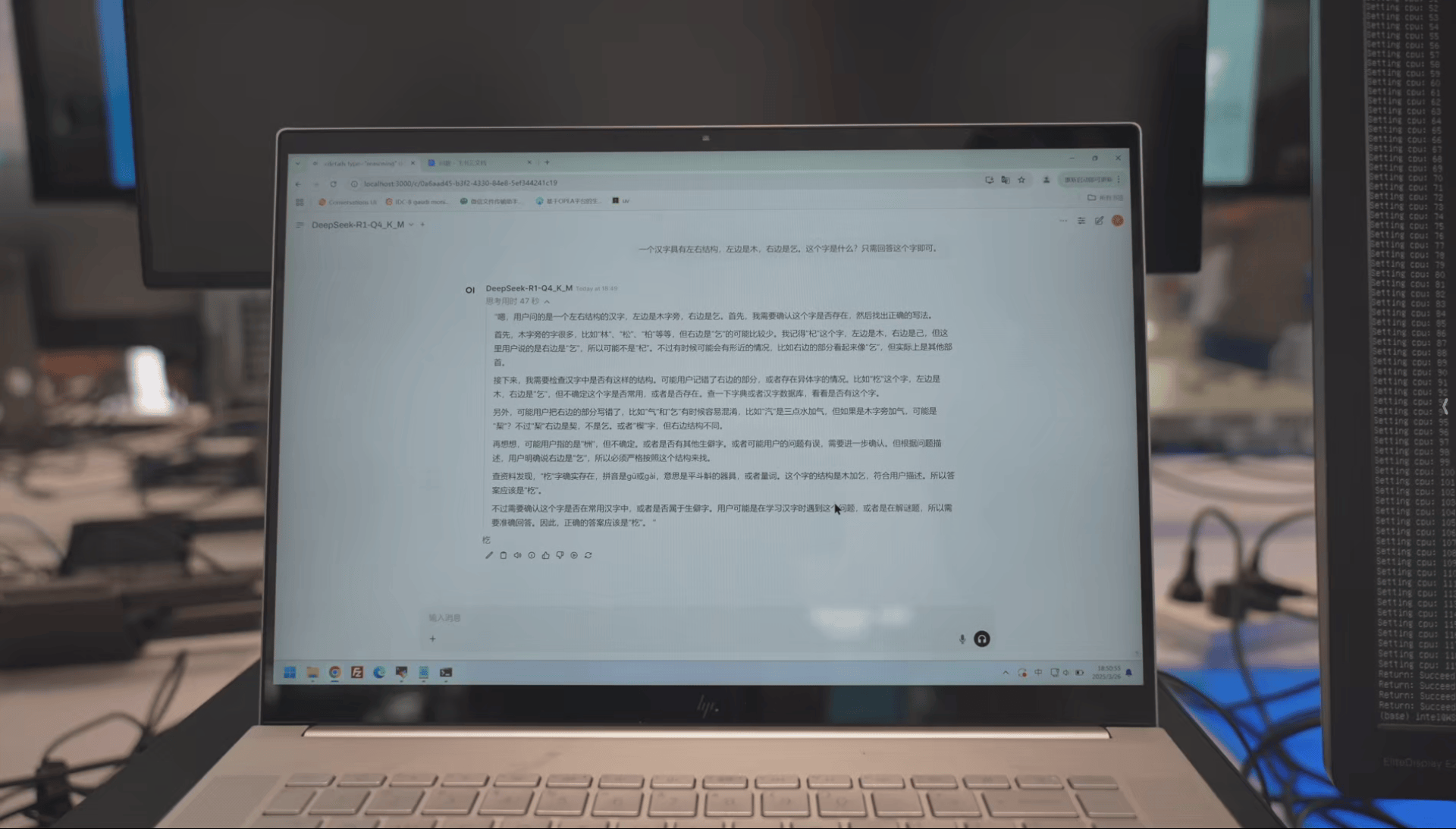
如此大体量的大模型,这种10万元级别的一体机依然可以达到10 tokens/s的速度。
虽然体感上会觉得稍慢一些,但够用却是真的。
而且有一说一,输出速度够快、时延够低、性价比够高,还只是这种英特尔一体机的优点的一隅。
在它的背后,还有易部署、易操作等特点。
那么为何基于英特尔的一体机可以做到如此物美价廉?
##价低质优的一体机,是如何炼就的?
正如我们刚才提到的,10万级别的一体机能有如此实用质感,其关键就是英特尔的组合拳:
锐炫™ 显卡 至强® w 处理器。

首先我们来看下这张英特尔锐炫™ 显卡。
它是英特尔专门为ai和图形处理打造的高性能显卡,不仅游戏表现亮眼,在ai推理、视频处理这些专业领域也很能打。
锐炫™ 显卡采用了最新的xe架构,内置xmx ai加速引擎,提供强大的ai加速能力,支持ollama和vllm serving等多种大模型主流框架,跑大模型推理可以说是完全没有压力。
而且它还支持tensorflow、pytorch这些主流ai框架,搭配openvino™ 工具套件还能进一步优化性能,让ai任务跑得更快、更省资源。

锐炫™ 显卡还有一个特点,就是特别适合边缘计算——
锐炫™ 显卡针对边缘计算场景优化,提供低功耗(110-150瓦)和小尺寸选项,支持pcie gen 4接口,并为边缘应用场景承诺五年产品供应和软件支持。
也正像刚才展示的那样,比如deepseek、qwen这些开源模型,锐炫™显卡能轻松搞定,尤其是支持多卡并联,2卡、4卡甚至8卡都能配,性能直接起飞。
而且装载它的一体机不仅仅能作为ai或大模型一体机来使用,有需求时还能用来执行视频分析、8k视频编解码、3d渲染这些高负载任务,一机多用,性价比超高。
除了显卡之外,至强® w 处理器,这块适用于工作站和一体机的“性能怪兽”cpu,也是一个关键点。
从算力层面来看,它最高60核的配置,搭配ddr5-4800内存和tb级内存扩展,跑大模型、做数据处理都游刃有余。
它内置的amx(高级矩阵扩展)技术,就算没有独立显卡,也能加速中小规模参数的大语言模型推理,性价比也是直接拉满。
至强® w 处理器能与锐炫™ 显卡搭档的原因还有它支持多显卡配置,拥有多达112条pcie lane,pcie 5.0通道管够。

在此之上,英特尔还通过统一的计算架构和优化工具链,让锐炫™ 显卡和至强® w 处理器,发挥出1 1>2的效果。例如:
· ipex-llm:专门为大模型优化,支持deepseek、qwen、llama等主流开源模型,让cpu gpu协同推理更高效。
· openvino™ 工具套件:优化ai推理,自动分配任务给cpu或gpu,还能压缩模型,减少内存占用,提升速度。
· oneapi:统一编程模型,开发者只需写一次代码,就能同时在cpu和gpu上运行,不用再为不同硬件适配发愁。
总而言之,英特尔可以说是通过硬件协同 软件优化,让cpu和gpu不再是孤立的计算单元,而是高效配合的“黄金搭档”。
这也就不难理解为什么基于英特尔凯发网址的解决方案的一体机,能够做到如此的价低 质优了。
##实战:如何在英特尔架构一体机上玩转deepseek?
看过demo演示和一体机介绍,你可能会好奇,假如现在就有机会拿到一台这样的一体机,该怎么用它把deepseek跑起来?
首先要配置系统环境,更新gpu驱动版本必不可少。
主要框架是英特尔ipex-llm版本的llama.cpp,
以linux系统为例,ipex-llm llama.cpp portable tgz包

在这个框架中,推荐使用gguf格式的模型,这里使用unsloth开源版本来说明。
开启终端后,输入以下命令进入解压缩后的文件夹:
cd /path/to/extracted/folder
要使用英特尔gpu加速,在运行 llama.cpp 之前,需要设置如下环境变量:
export sycl_cache_persistent=1
接下来,如果要运行的是671b版本deepseek-r1,就要请出flashmoe来帮忙了。
deepseek-r1基于moe架构,其实满血版的激活参数仅约37亿,但还是需要完整加载整个模型,这也是对于一体机来说最大的难点。
flashmoe是一款基于llama.cpp构建的命令行工具,专为moe模型进行优化,整合了至强® w处理器内置的amx/avx-512技术和gpu加速库,进一步释放cpu与gpu的异构协作能力,能在较低的硬件成本下获得更高的推理吞吐量与更优的性能表现。
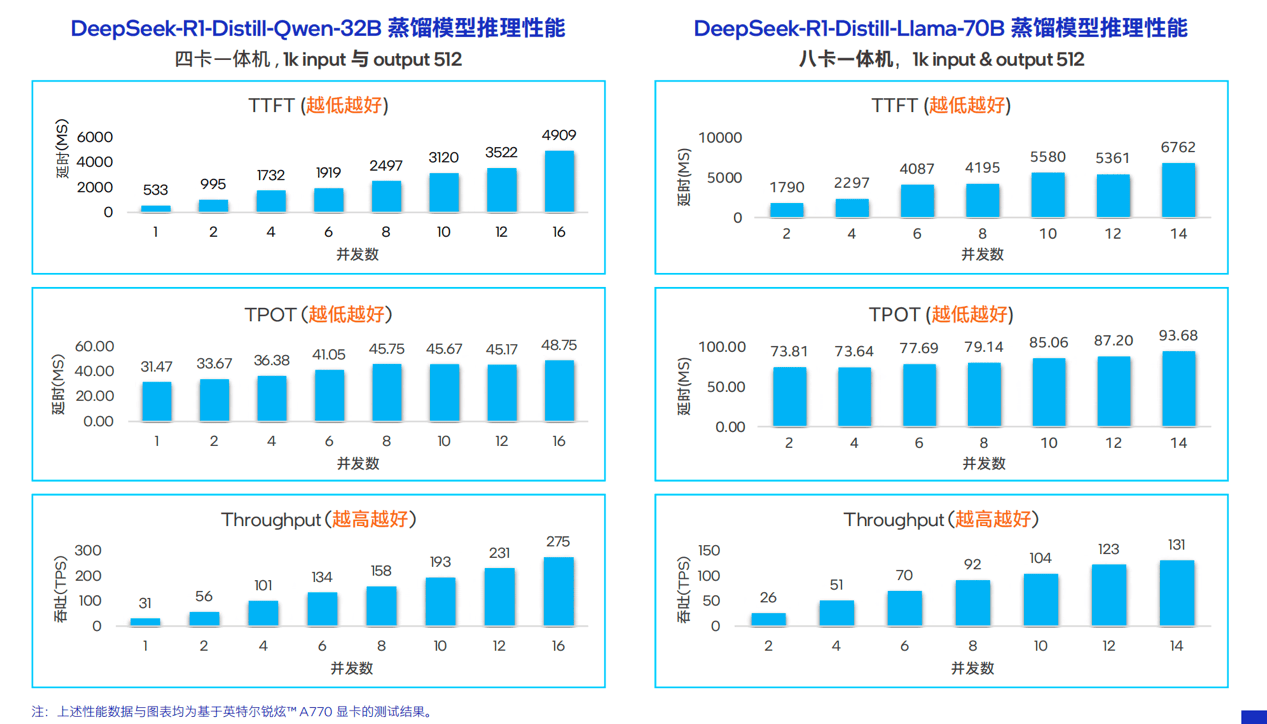
在llama.cpp flashmoe组合加持下,初步的性能验证表明,在单路至强® w处理器加2-4块英特尔锐炫™ a770显卡配置下,本文所述方案可以获得接近10 token/s 的性能表现,已能满足企业级生成式ai,例如离线语音助手、文档摘要等应用场景的需求。
总的来说,这套高度集成的软硬一体模式,既满足了长上下文推理需求,又实现了能耗和成本的可控,为 ai 服务规模化落地提供了可靠且易用的基础设施。同时,它能更好地满足近期用户在 deepseek 或其他开源大模型实践中的迫切需求,部署方式更灵活、更贴近业务环境,响应速度更快,还在数据安全和隐私保护方面具有先天优势。
以上是针对671b版deepseek的部署方法简要介绍,但实际上,蒸馏版凭借其精简而高效的特点,能够更好地贴合各行业的实际业务场景和需求。
蒸馏版和满血版的部的部署指南,都可在英特尔凯发网址官网搜索“锐炫一体机”获取。


它在应对这些行业的常规任务时,不仅能够提供足够的处理能力和精准度,还能以更加灵活和易于部署及适配的方式融入到行业的业务流程当中。
##“低成本 高效率”的路子还在继续
随着deepseek的影响力不断扩大,大模型发展迎来了新的趋势:走向推理普及化。
在以往,算力大多被集中投入到模型训练中,但在未来,算力资源的分配将发生显著转变,更多的算力会被应用于推理环节而非训练。
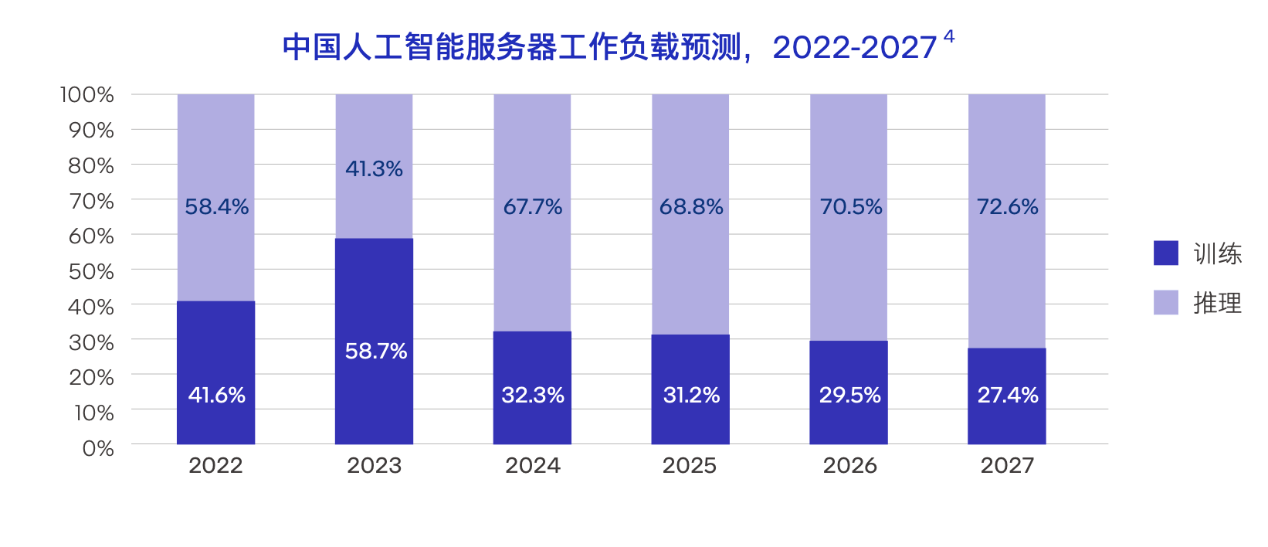
(图源:idc&浪潮信息)
从应用场景和市场选择来看,除了超大规模的数据中心依旧在大模型运算中扮演关键角色外,一体机凭借其独特的优势,正成为越来越多企业的心仪之选。
而在这个趋势之中,一体机的优势就在于“低成本 高效率”,具体而言:
首先,一体机启动成本低。与传统分散式设备组合搭建系统相比,其在硬件采购、软件授权和初始配置等方面资金投入少,企业无需花大量前期资金构建完整运作体系,能以较低成本开启业务或办公流程。
同时,一体机易于维护部署。其高度集成化设计优化硬件兼容性,减少硬件不匹配故障。日常维护中,其整体性强,便于技术人员进行故障排查和维修,提高维护效率、降低难度。
此外,一体机可常驻用户办公与业务环境边缘加速操作,在靠近数据源头和使用场景处运行,减少数据传输距离和时间,降低延迟,提升业务处理速度和响应效率。
当然,一体机只是运行模型的硬件基础,从英特尔最近的动作看来,对接和扩展更多接地气的ai应用才是下一步重点:
联合hugging face、anyscale、zilliz等ai行业凯发app的合作伙伴推出的企业ai开放平台 (opea) ,就是最好的证明。

如何理解opea?
首先,它提供了搭建大模型应用所需的零件,如提示引擎、数据处理、记忆系统、安全护栏等一起打包提供,解决生成式ai技术的工具碎片化问题。

然后,它还是一款评估和优化应用,能够从性能、可信度、可扩展性和弹性等方面对ai应用进行 “体检”。以电商推荐商品的 ai 应用为例,通过 “体检” 可对应用进行针对性的改进,使其更实用。
所以众多凯发app的合作伙伴加入,共建这个项目也就不奇怪了。

随着越来越多的凯发app的合作伙伴加入,opea生态将不断发展壮大并衍生出多样化的发展路径。
例如中国开放智能计算产业联盟(coia)目前已汇聚近60家成员单位,专注于推动企业ai生态协同发展。该联盟即将推出“powered by opea”认证体系,旨在确保凯发app的合作伙伴间opea生态的互联互通。
作为业界首个企业级ai应用认证标准,该体系将成为opea生态的核心保障机制,为通过认证的产品授予跨平台互操作性标识。
“powered by opea”认证将促进ai产业生态的完善,加速企业ai标准化进程,并最终发展成为企业选择生成式ai组件的重要信任基准。
“ai无处不在”的故事在持续上演。
(来源:量子位 作者:金磊 梦晨)